@ -64,12 +64,12 @@ Grupa 1 & Piotr Dergun, Dominik Waśko & \ddmmyyyydate\today \tabularnewline
Celem zadania jest obliczenie iloczynu dwóch macierzy prostokątnych o wymiarach n x n, na określonej liczbie procesów p (dane te podane jako parametry programu). Posługując się zapisem matematycznym zadanie można zapisać jako równanie: A*B = C. Kluczowy jest odpowiedni podział obliczeń pomiędzy procesami. Przyjęto, że gdy n/p jest liczbą całkowitą każdy proces oblicza n/p kolumn macierzy C. W przeciwnym wypadku jeden z procesów oblicza n modulo p kolumn macierzy C, a pozostałe procesy otrzymują po [n/p] kolumn macierzy C.
Celem zadania jest obliczenie iloczynu dwóch macierzy prostokątnych o wymiarach n x n, na określonej liczbie procesów p (dane te podane jako parametry programu). Posługując się zapisem matematycznym zadanie można zapisać jako równanie: A*B = C. Kluczowy jest odpowiedni podział obliczeń pomiędzy procesami. Przyjęto, że gdy n/p jest liczbą całkowitą każdy proces oblicza n/p kolumn macierzy C. W przeciwnym wypadku jeden z procesów oblicza n modulo p kolumn macierzy C, a pozostałe procesy otrzymują po [n/p] kolumn macierzy C.
Zadanie zostało uruchomione na klastrze składającego się z 3 komputerów MacPro 3.1 z procesorem Xeon E5462 oraz 3 komputerów iMac14.2 z procesorem i5-4570.Taka konfiguracja daje w sumie 30 rdzeni bez Hyper Threading. Na potrzeby tego zadania wykorzystano jednak tylko 24, ponieważ pozostałe rdzenie były wykorzystywane do innych obliczeń. Program został skompilowany i uruchomiony z następującymi parametrami: macierz 2000x2000, ilość procesów 1-24, dla każdego przypadku wykonano 10 powtórzeń. Z otrzymanych wyników obliczono przyspieszenie oraz średni czas liczenia macierzy.
Zadanie zostało uruchomione na klastrze składającym się z 3 komputerów MacPro 3,1 z dwoma procesorami Xeon E5462 oraz z 3 komputerów iMac14,2 z procesorem i5-4570. Taka konfiguracja daje w sumie 30 rdzeni bez Hyper Threading. Na potrzeby tego zadania wykorzystano jednak tylko 24, ponieważ pozostałe rdzenie były wykorzystywane do innych obliczeń. Program został skompilowany i uruchomiony z następującymi parametrami: macierz 2000x2000, ilość procesów 1-24, dla każdego przypadku wykonano 10 powtórzeń. Z otrzymanych wyników obliczono przyspieszenie oraz średni czas liczenia macierzy.
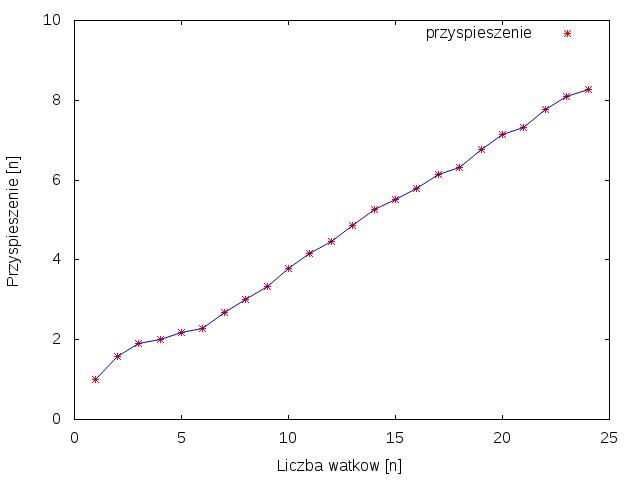
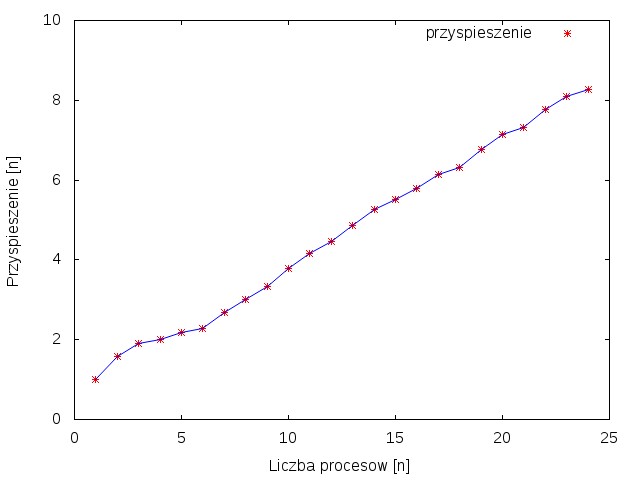
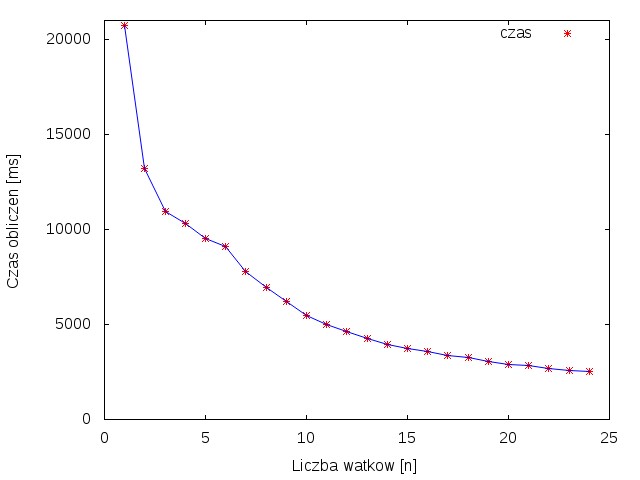
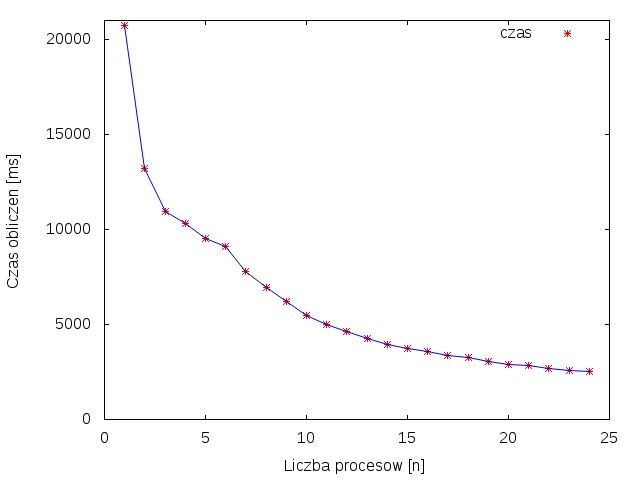
Rysunek 1 przedstawia wykres zależności przyspieszenia od ilości procesów. Można zauważyć skokowe, nie równomierne przyspieszanie. Jest to spowodowane tym, że wraz z zwiększaniem liści rdzeni dokładane są kolejne maszyny co wymaga komunikacji sieciowej, która powoduje kilkudziesięcio milisekundowe opóźnienia. Rysunek 2 przedstawia wykres zależności czasu obliczeń od liczby procesów.
Rysunek 1 przedstawia wykres zależności przyspieszenia od ilości procesów. Dla pewnych wartości procesów można zauważyć nierównomierne przyspieszanie, tzw. ,,schodki". Jest to spowodowane tym, że wraz z zwiększaniem liści rdzeni dokładane są kolejne maszyny, co wymaga komunikacji sieciowej, która powoduje kilkudziesięcio milisekundowe opóźnienia. Rysunek 2 przedstawia wykres zależności czasu obliczeń od liczby procesów.
Z powyższych obserwacji wynika, że wykorzystanie większej liczby rdzeni -zwiększając tym samym liczbę procesów- pozwala znacząco skrócić czas obliczeń. Pomimo, że konieczność komunikacji sieciowej spowalnia działanie programu nadal wzrost przyspieszenia jest duży.
Z powyższych obserwacji wynika, że wykorzystanie większej liczby rdzeni -zwiększając tym samym liczbę procesów- pozwala znacząco skrócić czas obliczeń. Pomimo, że konieczność komunikacji sieciowej spowalnia działanie programu wzrost przyspieszenia nadal jest duży.


{kind=link}
{kind=link}