Problem jest dzielony w ten sposób, że każdy z procesów dostaje określoną ilość wierszy do przetworzenia (zmienna porcja). Porcja jest obliczania jako stosunek liczby wierszy do liczby procesów. Ostatni proces może przetwarzać inną liczbę procesów, wyrażoną jako różnicę liczby wierszy i iloczynu pozostałych wątków oraz porcji. Ze względu na to, ostatni proces może mieć mniej lub więcej wierszy do liczenia. Do odsyłania nowych obrazów posłużono się funkcją MPI\_Gatherv, która pozwala scalać kawałki różnej długości.
@ -98,11 +124,9 @@ Zmienne \textit{i} oraz \textit{j} służą do iteracji po wszystkich pikselac
Do wczytania obrazu użyto biblioteki OpenCV.
Do wczytania obrazu użyto biblioteki OpenCV.
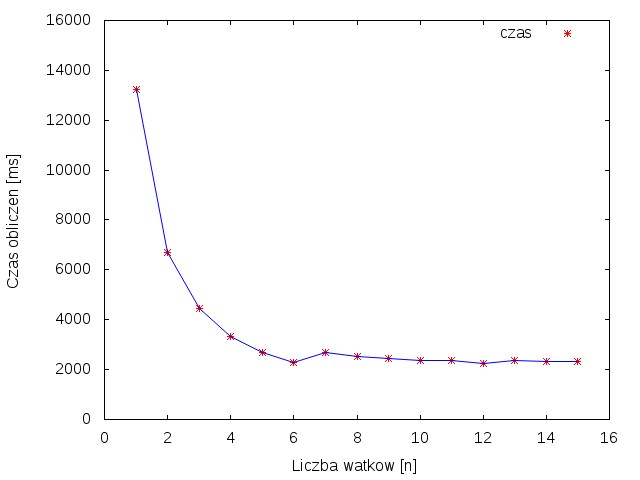
Zadanie zostało uruchomione na komputerze MacPro3,1 wyposażonym w 2 procesory Xeon E5462, przy czym do dyspozycji było 6 rdzeni.
Program został uruchomiony dla obrazu o rozmiarze AxB. Obliczenia przeprowadzono tworząc od 1 do 15 wątków, dla każdej ilości wykonano 10 powtórzeń. Z otrzymanych wyników obliczono przyspieszenie oraz średni czas obliczania rozmycia.
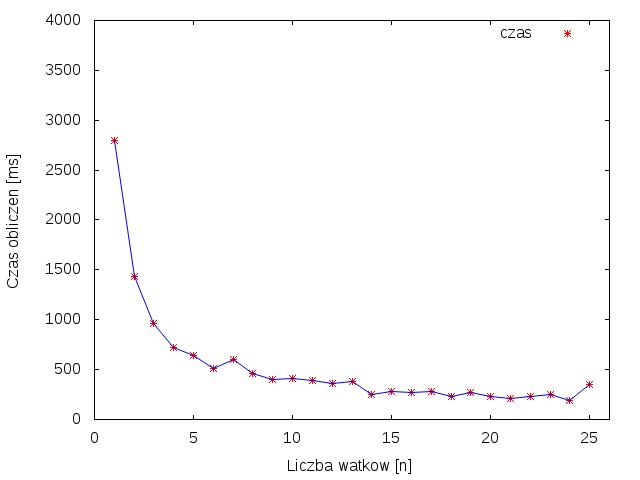
Zadanie zostało uruchomione dla obrazu o rozmiarze 2592x13824 px, na klastrze składającym się z 3 komputerów MacPro3,1 z dwoma procesorami Xeon E5462 oraz z 3 komputerów iMac14,2 z procesorem i5-4570. Taka konfiguracja daje w sumie 30 rdzeni bez Hyper Threading. Na potrzeby tego zadania wykorzystano jednak tylko 24, ponieważ pozostałe rdzenie były wykorzystywane do innych obliczeń. Obliczenia przeprowadzono tworząc od 1 do 25 procesów, dla każdej ilości wykonano 10 powtórzeń. Z otrzymanych wyników obliczono przyspieszenie oraz średni czas obliczania rozmycia.
Rysunek 1 przedstawia wykres zależności przyspieszenia od ilości wątków. Można na nim zauważać że wzrost przyspieszenia uzyskuje się tylko do momentu gdy liczba wątków jest mniejsza lub równa ilości rdzeni. Powyżej sześciu następuje już przetwarzanie współbieżne. Rysunek 2. przedstawia wykres zależności czasu obliczeń od liczby wątków. Można zobaczyć na nim, że powyżej 6 wątków czas obliczeń nie ulega już skróceniu.
Rysunek 1 przedstawia wykres zależności przyspieszenia od ilości procesów. Można na nim zauważać że wzrost przyspieszenia uzyskuje się tylko do momentu gdy liczba procesów jest mniejsza lub równa ilości rdzeni. Powyżej 24 następuje już przetwarzanie współbieżne. Dla pewnych liczb procesów można zauważyć nierównomierne przyspieszanie, tzw. „schodki”. Jest to spowodowane tym, że synchronizacja sieciowa obejmuje kolejne maszyny, a czas obliczeń tak naprawdę jest czasem obliczeń najwolniejszej maszyny. W związku z tym, jeżeli któraś z maszyn chwilowo była zajęta przetwarzaniem innych informacji i zadanie cząstkowe na jakiejś maszynie liczyło się przez krótki okres czasu współbieżnie, zaważy to na stabilności czasów dla całego zadania. Rysunek 2. przedstawia wykres zależności czasu obliczeń od liczby procesów. Można zobaczyć na nim, że powyżej 24 wątków czas obliczeń nie ulega już skróceniu.
Z powyższych obserwacji wynika, że wykorzystanie większej liczby wątków pozwala znacząco skrócić czas wykonania programu. Jednak zwiększanie liczby wątków ponad to co oferuje procesor nie powoduje wzrostu wydajności i wymusza współbieżne liczenie.
Z powyższych obserwacji wynika, że wykorzystanie większej liczby wątków pozwala znacząco skrócić czas wykonania programu. Jednak zwiększanie liczby wątków ponad to co oferuje procesor nie powoduje wzrostu wydajności i wymusza współbieżne liczenie.


{kind=link}
{kind=link}

